
El estudio de determinadas características de una población se efectúa a través de diversas muestras que pueden extraerse de ella.
El muestreo puede hacerse con o sin reposición, y la población de partida puede ser infinita o finita. Una población finita en la que se efectúa muestreo con reposición puede considerarse infinita teóricamente. También, a efectos prácticos, una población muy grande puede considerarse como infinita. En todo nuestro estudio vamos a limitarnos a una población de partida infinita o a muestreo con reposición.
Consideremos todas las posibles muestras de tamaño n en una población. Para cada muestra podemos calcular un estadístico (media, desviación típica, proporción,...) que variará de una a otra. Así obtenemos una distribución del estadístico que se llama distribución muestral.
Las dos medidas fundamentales de esta distribución son la media y la desviación típica, también denominada error típico.
Hay que hacer notar que si el tamaño de la muestra es lo suficientemente grande las distribuciones muestrales son normales y en esto se basarán todos los resultados que alcancemos.
Si tenemos una muestra aleatoria de una población N(m,s ), se sabe (Teorema del límite central) que la fdp de la media muestral es también normal con media m y varianza s2/n. Esto es exacto para poblaciones normales y aproximado (buena aproximación con n>30) para poblaciones cualesquiera. Es decir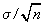 es el error típico, o error estándar de la media.
es el error típico, o error estándar de la media.
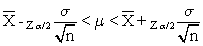
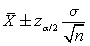
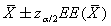
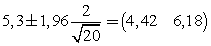
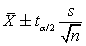
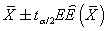
Si tenemos una muestra aleatoria de una población N(m,s ), se sabe (Teorema del límite central) que la fdp de la media muestral es también normal con media m y varianza s2/n. Esto es exacto para poblaciones normales y aproximado (buena aproximación con n>30) para poblaciones cualesquiera. Es decir
¿Cómo usamos esto en nuestro problema de estimación?
1º problema: No hay tablas para cualquier normal, sólo para la normal m=0 y s=1 (la llamada z); pero haciendo la transformación (llamada tipificación)
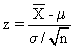
una normal de media m y desviación s se transforma en una z.
1º problema: No hay tablas para cualquier normal, sólo para la normal m=0 y s=1 (la llamada z); pero haciendo la transformación (llamada tipificación)
una normal de media m y desviación s se transforma en una z.
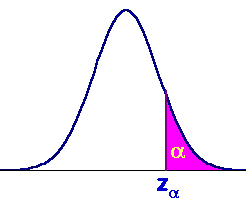 |
Llamando za al valor de una variable normal tipificada que deja a su derecha un área bajo la curva de a, es decir, que la probabilidad que la variable sea mayor que ese valor es a(estos son los valores que ofrece la tabla de la normal)
|
podremos construir intervalos de la forma
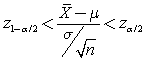
para los que la probabilidad es 1 - a.
|  |
Teniendo en cuenta la simetría de la normal y manipulando algebraícamente
o, haciendo énfasis en que es el error estándar de la media,
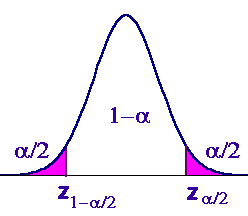
Recuérdese que la probabilidad de que m esté en este intervalo es 1 - a. A un intervalo de este tipo se le denomina intervalo de confianza con unnivel de confianza del 100(1 - a)%, o nivel de significación de 100a%. El nivel de confianza habitual es el 95%, en cuyo caso a=0,05 y za /2=1,96. Al valor  se le denomina estimación puntual y se dice que es un estimador de m.
se le denomina estimación puntual y se dice que es un estimador de m.
Ejemplo: Si de una población normal con varianza 4 se extrae una muestra aleatoria de tamaño 20 en la que se calcula 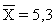 se puede decir que mtiene una probabilidad de 0,95 de estar comprendida en el intervalo
se puede decir que mtiene una probabilidad de 0,95 de estar comprendida en el intervalo
que sería el intervalo de confianza al 95% para m
En general esto es poco útil, en los casos en que no se conoce m tampoco suele conocerse s2; en el caso más realista de s2 desconocida los intervalos de confianza se construyen con la t de Student (otra fdpcontinua para la que hay tablas) en lugar de la z.
o, haciendo énfasis en que 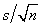 es el error estándar estimado de la media,
es el error estándar estimado de la media,
Este manera de construir los intervalos de confianza sólo es válido si la variable es normal. Cuando n es grande (>30) se puede sustituir t por zsin mucho error.
No hay comentarios:
Publicar un comentario
Nota: solo los miembros de este blog pueden publicar comentarios.